


 Your new post is loading...
Your new post is loading...

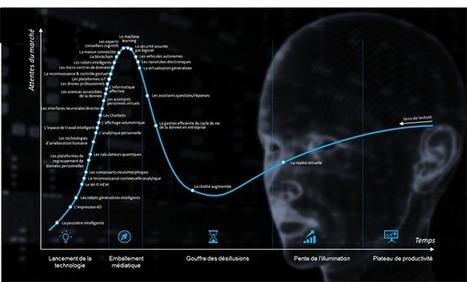

A la croisée de beaucoup de technologies, les méthodes sous-jacentes liées à l’IA ont énormément évoluées ces dernières années et se sont diversifiées.
L’IA qui est intrinsèquement liée au Big Data, profite depuis les années 2000 d’un environnement technologique opportun, avec la montée en puissance de traitements des machines, des architectures distribuées autant côté calcul que stockage et bien évidemment du marché mobile et des objets connectés générant de plus en plus de données.







{kind=link}
Les domaines pouvant tirer profit du Deep Learning sont multiples et leur développement vont à coup sûr modifier nos habitudes. Le marketing digital va s’orienter progressivement vers une personnalisation et un ciblage de plus en plus fin. En parallèle les consommateurs, contribuant à enrichir les données, verront leur expérience utilisateur améliorée. Et que dire des promesses dans le domaine de la santé, des voitures autonomes, de l’industrie agroalimentaire, de la robotique pour ne citer qu’eux.
Cependant, quelques inquiétudes légitimes, la première portant sur la gouvernance des données collectées, et la seconde mettant l’accent sur l’effet “boîte noire” de l’apprentissage autonome des machines, car l’audit des résultats prédictifs n’est pas réellement maîtrisable. Cette perte de contrôle renforce les défenseurs de la théorie de la singularité (bien qu’elle ne repose sur aucun fondements scientifiques) qui laisse entendre que la machine prendrait le pas sur l’homme en prenant conscience d’elle-même.